#_자료구조 : 효율적으로 데이터를 관리하고 수정, 삭제, 탐색, 저장할 수 있는 데이터 집합, C++는 STL을 기반으로 전반적인 자료구조를 잘 설명할 수 있는 언어
*STL : C++의 표준 템플릿 라이브러리이자 스택, 배열 등 데이터 구조의 함수 등을 제공하는 라이브러리 묶음
#include <bits/stdc++.h> //(1)
using namespace std; //(2)
string a; //(3)
int main()
{
cin >> a; //(4)
cout << a << "\n"; //(5)
return 0; //(6)
}(1) : 헤더파일, STL라이브러리 import
(2) : std라는 네임스페이스(같은 클래스 이름 구별, 모듈화에 쓰이는 이름) 사용
(3) : 문자열 선언, <타입><변수명> 선언, string a="apple"에서 a는 추후 다시 사용되는 lvalue, apple은 다시 사용되지 않는 rvalue
(4) : 입력
(5) : 출력
(6) : 프로세스가 정상적으로 마무리됨
#_시간 복잡도 : 문제를 해결하는데 걸리는 시간과 입력의 함수 관계, 어떠한 알고리즘의 로직이 얼마나 오랜시간이 걸리는지 나타내는데 사용, 일반적으로 빅오 표기법 사용
#_빅오표기법 : 입력범위 n을 기준으로 로직이 몇번 반복되는지 나타냄, 시간복잡도의 빅오표기법(O(n^2))
#_시간복잡도의 존재이유 : 효율 코드 개선시 사용되는 속도

#_공간복잡도 : 프로그램을 실행시켰을 때 필요로 하는 자원공간의 양, 정적변수뿐만 아니라 동적으로 재귀적인 함수로 인해 공간을 계속해서 필요로 할 경우 포함
#_자료구조에서의 시간복잡도

#_연결리스트 : 데이터를 감싼 노드를 포인터로 여결해서 공간적인 효율성을 극대화시킨 자료구조, 삽입과 삭제는 O(1), 탐색은 O(n) 소요, 데이터 추가와 삭제를 많이 할 때 권장
| 싱글 연결 리스트 | next 포인터만 가짐 |
| 이중 연결 리스트 | next 포인터와 prev 포인터 가짐 |
| 원형 이중 연결 리스트 | 이중 연결 리스트와 같지만 마지막 노트의 next 포인터가 헤드 노드를 가리킴 |

#_배열 : 같은 타입의 변수들로 이루어지고 크기가 정해져있으며 인접한 메모리위치에 있는 데이터를 모아놓은 집합, 중복허용, 순서가 있음, 인덱스에 해당하는 원소를 빠르게 접근하거나 간단한 데이터를 쌓을 때 사용하므로 탐색을 많이할 때 권장
#_랜덤접근 : 직접 접근, 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능
#_순차적접근 : 데이터를 저장된 순서대로 검색
| 배열 | 연결 리스트 |
| 상자를 순서대로 나열한 구조로 상자의 인덱스를 알면 해당 상자의 요소 탐색가능 |
상자를 선으로 연결한 형태의 데이터 구조로 상자내부의 요소를 알기위해서는 하나씩 상자 내부를 확인해야함 |
| 탐색이 빠름 | 탐색이 느림 |
| 데이터 추가 및 삭제 느림 | 데이터 추가 및 삭제 빠름 |
#_벡터와 push_back()의 시간복잡도가 O(1)인 이유
#_스택 : 가장 마지막에 들어간 데이터가 가장 첫번째로 나오는 성질(LIFO)을 가진 자료구조, 재귀적인 함수, 알고리즘에 사용되며 웹 브라우저 방문 기록 등에 쓰임, 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸림
#_큐 : 먼저 집어넣은 데이터가 먼저 나오는 성질(FIFO)을 지닌 자료구조, 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸림, CPU작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행렬, 너비우선 탐색, 캐시 등에 사용
#_그래프 : 정점과 간선으로 이루어진 자료구조
#_정점과 간선 : 정점=목적지, 간선=방식
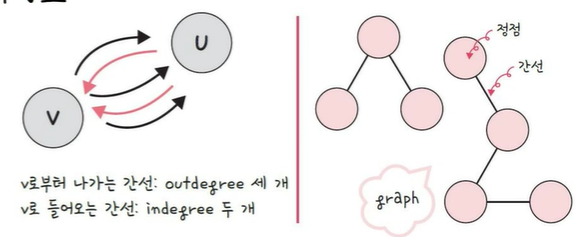
#_가중치 : 간선과 정점사이에 드는 비용
#_트리 : 그래프의 일종으로 정점과 간선으로 이루어져있고 트리구조로 배열된 일종의 계층적 데이터 집합, 부모 자식 계층 구조를 가짐, V-1=E(간선수=노드수-1), 두 노드사이의 경로는 유일무이하게 존재함
| 트리의 구성 |
루트노드 | 가장 위에 있는 노드 |
| 내부노드 | 루트노드와 내부노드 사이의 노드 | |
| 리프노드 | 자식노드가 없는 노드 |
| 트리의 높이와 레벨 |
깊이 | 각 노드마다 다르며 루트노드부터 특정노드까지의 최단 거리 |
| 높이 | 루트노드부터 리프노드까지의 거리 중 가장 긴 거리 | |
| 레벨 | 루트노드부터 특정노드까지의 최단 거리 | |
| 서브트리 | 트리 내의 하위집합, 트리 내의 부분집합 |
#_이진트리 : 자식의 노드수가 두개 이하인 트리
| 정이진트리 | 자식 노드가 0 또는 두개인 이진트리 |
| 완전 이진 트리 | 왼쪽부터 채워진 이진트리, 마지막 레벤을 제외한 모든 레벨이 채워짐, 마지막 레벨은 왼쪽부터 채워짐 |
| 변질 이진 트리 | 자식 노드가 하나뿐인 이진트리 |
| 포화 이진 트리 | 모든 노드가 꽉 찬 이진트리 |
| 균형 이진 트리 | 왼쪽과 오른쪽의 높이 차이가 1이하인 이진트리, map, set을 구성하는 레드 블랙트리가 있음 |
| 이진 탐색 트리 | 오른쪽 하위는 노드값보다 큰 값만 포함, 왼쪽 하위는 노드값보다 작은값만 포함하는 트리 |

#_균형잡힌 트리
- AVL 트리 : 최악의 경우 선형적인 트리가 되는 것을 방지하고 스스로 균형을 잡음, 두 자식 서브트리의 높이는 항상 최대 1만틈 차이남, 탐색, 삽입, 삭제 모두 시간 복잡도 O(log n), 삽입, 삭제시마다 균형이 안맞는 것을 맞추기 위해 트리 일부를 왼쪽 혹은 오른쪽으로 회전시키며 균형을 잡음
- 레드블랙트리 : 탐색, 삽입, 삭제 모두 시간 복잡도 O(log n), 각 노드는 빨, 검 색을 나타내는 추가 비트를 저장하며 삽입 및 삭제 중에 트리가 균형을 유지하는데 사용, '모든 리프노드와 루트노드는 블랙이며 어떤 노드가 레드이면 그 노드의 자식은 반드시 블랙'의 규칙을 기반으로 균형을 잡는 트리
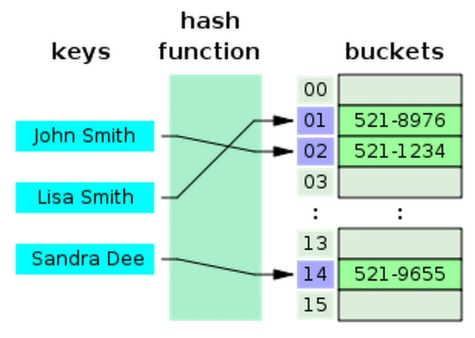
#_해시테이블 : 무한에 가까운 데이터들을 유한한 개수의 해시값으로 매핑한 테이블, 삽입, 삭제, 탐색시 평균 O(1)의 시간복잡도를 가지며 최악의 경우 O(n)의 시간복잡도를 가짐
- 해시 : 다양한 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 값
- 해싱 : 임의의 데이터를 해시로 바꿔주는 일을 하며 해시함수가 이를 담당
- 해시함수 : 임의의 데이터를 입력받아 일정한 길이의 데이터로 바꿔주는 함수
#_LRU : 참조가 가장 오래된 페이지를 바꾸는 알고리즘(원래는오래된 것을 파악하기 위해 계수기, 스택을 두어야 함)
*오래된 것 : 리스트의 가장 마지막 요소
*최근에 참조된 것 : 리스트의 가장 첫번째 요소
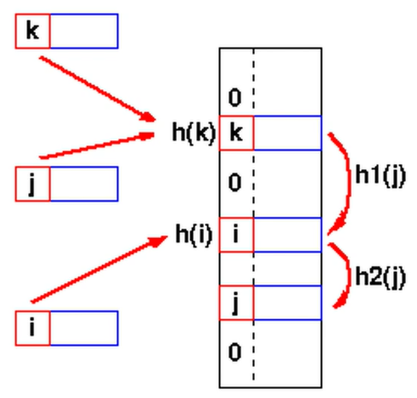
#_해시충돌문제 발생 : 해시값이 같은 값이 발생할 때 충돌 발생, 매우 큰 테이블이여도 발생됨
#_해시충돌문제 해결
- 체이닝 : 충돌시 연결리스트에 할당, 충돌시 연결리스트 탐색
장점) 구현간단, 해시테이블에 많은 데이터를 넣을 수 있음
단점) 연결리스트 기반이라 캐시성능이 좋지않음, 체인이 길어지면 최악의 경우 O(n)이 될 수 있음
#_개방 주소법 : 충돌시 다른 버킷에 데이터 삽입
- 선형 탐색 : 해시충돌시 다음 버켓, 혹은 몇개를 선형적으로 건너뛰어 데이터 삽입
- 제곱 탐색 : 해시충돌시 제곱만큼 건너뛴 버켓에 데이터 삽입
- 이중 해시 : 해시충돌시 다른 해시함수를 한 번 더 적용한 결과를 이용해서 데이터 삽입
#_로또번호를 셔플하기위한 가장 좋은 자료구조?

'CS 지식 > [inflearn] CS 전공지식 (완)' 카테고리의 다른 글
| 개발자면접을 위한 CS전공지식 | CS면접 - 데이터베이스 (0) | 2022.07.28 |
|---|---|
| 개발자면접을 위한 CS전공지식 | CS면접 - 운영체제 (0) | 2022.07.19 |
| 개발자면접을 위한 CS전공지식 | CS면접 - 네트워크 (0) | 2022.07.14 |
| 개발자면접을 위한 CS전공지식 | CS면접 - 디자인패턴 (0) | 2022.07.12 |